
Reflexiones sobre GPT-5, por qué la IA no ha llegado al limite, y la creciente dependencia emocional de la sociedad hacia los chatbots
Este articulo es una traducción de el articulo original en ingles. Si tu nivel de ingles es bueno, te recomiendo leer la version original, ya que muchas de las palabras y conceptos relacionados a todo el ecosistema AI no tienen una traducción perfecta al español, por lo que la historia se cuenta mejor en su lenguaje original.
OpenAI lanzó GPT-5 el jueves pasado (7 de agosto de 2025), y la comunidad tech en Twitter y Reddit han estado como locos desde entonces. Hay algunas personas impresionadas, algunas enfurecidas, y otras súper tristes porque perdieron (y recientemente recuperaron) a su querido gpt-4o.
Durante el fin de semana, leí miles de tweets, cientos de posts de Reddit, etc., y mi mente no estaba completamente organizada, así que decidí escribir, porque eso es lo que siempre hago cuando necesito encontrar claridad en mis pensamientos.
Voy a explorar tres historias paralelas aquí—reflexiones sobre GPT-5, el ritmo del progreso de la IA, y las extrañas dinámicas sociales que están emergiendo—y todas convergerán en una conclusión.
Puede que empiece con algunas afirmaciones obvias, pero no te preocupes—sigue leyendo y las cosas harán clic. O salta a la sección 2 si prefieres.
Empecemos.
1. Reflexiones sobre GPT-5
Ha habido modelos LLM increíbles lanzados en 2025, y siendo justo, no creo (pero sí entiendo) que el lanzamiento de GPT-5 merezca la enorme atención que ha recibido. A diferencia de 2023, cuando OpenAI tenía una clara ventaja en el camino de la IA, eso ya no es el caso (básicamente están codo a codo con otros laboratorios ahora, y claramente han perdido mucho de su gran equipo).
Ha habido algunos lanzamientos enormes de modelos este año que presentaron resultados impresionantes, y creo que GPT-5 es solo uno de ellos. Pero digámoslo directamente:
GPT-5 es un gran modelo, y aún más importante, se ofrece a un precio increíble.
¿Fue un salto como GPT-3 a GPT-4? Definitivamente no, pero hablare mas sobre eso después.
Hablando ahora sobre la experiencia de GPT-5 en ChatGPT (que es diferente del modelo GPT-5 desde la API), creo que hubo cosas buenas y malas:
Creo que la unificación del modelo fue una buena idea para la mayoría de usuarios (no todos), ya que da una UX mucho más fácil para usuarios que no son tech-savvy, permitiéndoles interactuar con una IA mucho más inteligente, sin entender los nombres técnicos de modelos como o4-mini-high, gpt-4.1, etc.
Pero mientras fue bueno para el el usuario promedio, los power users, que entienden perfectamente los pros y contras de cada modelo, hubieran preferido poder elegir, no solo tener un router eligiendo por ellos.
Hasta que tengamos una AGI verdadera que sepa mejor que nosotros mismos qué modelo es el mejor para cada consulta, creo que esa idea del router simplemente no es lo que los power users quieren o deberían tener. Deberíamos haber tenido ambas opciones.
Ahora, mirando las capacidades reales del modelo: Tiene puntuaciones increíbles en la mayoría de benchmarks, presenta un gran salto en la reducción de alucinaciones, es rápido, y tiene una mejor personalidad en general (en mi opinión) que GPT-4o, que tenía una personalidad aduladora que incluso después de ser nerfeada, permanecía bastante presente.
En resumen, al menos para mí, GPT-5 fue un lanzamiento 'suficientemente bueno', con un precio excelente.
Continuemos con la siguiente parte.
2. ¿Se está ralentizando el progreso en IA?
O si prefieres el enfoque: "¿Ya la IA ha tocado techo?", repasemos esta pregunta.
Desde mi perspectiva, la respuesta a esta pregunta es un claro no, y déjame darte algunas ideas.
La mayoría de las nuevas tecnologías pasan por una curva S, en la cual empiezan lentamente, luego tienen un progreso enorme, y después continúan planas, igual que al principio.
El tema es que creo que nuestra tendencia a: (1) sobrevalorar todo en el espacio de IA (en la mayoría de casos, completamente culpa de muchos de los laboratorios de IA y sus promesas excesivas y declaraciones vagas de expectativas), (2) adaptarnos increíblemente rápido a nuevas tecnologías, y (3) juzgar el progreso a través de un lente demasiado estrecho nos hace creer que es el caso que nos estamos ralentizando, cuando las probabilidades son que es completamente lo opuesto.
Aquí va un ejemplo personal: Al final de casi todos los años, siento que no he logrado nada.
Así que me obligo a tomar 1-2 días completos para escribir lo que he aprendido, qué nuevos proyectos/negocios he lanzado, qué nuevas habilidades he desarrollado, etc., y al final, siempre siento que es todo lo contrario, así que haré lo mismo ahora con la IA, y te daré algunas comparaciones.
Esto podría volverse locamente largo, así que me enfocaré en las comparaciones centrales de progreso para evitar eso.
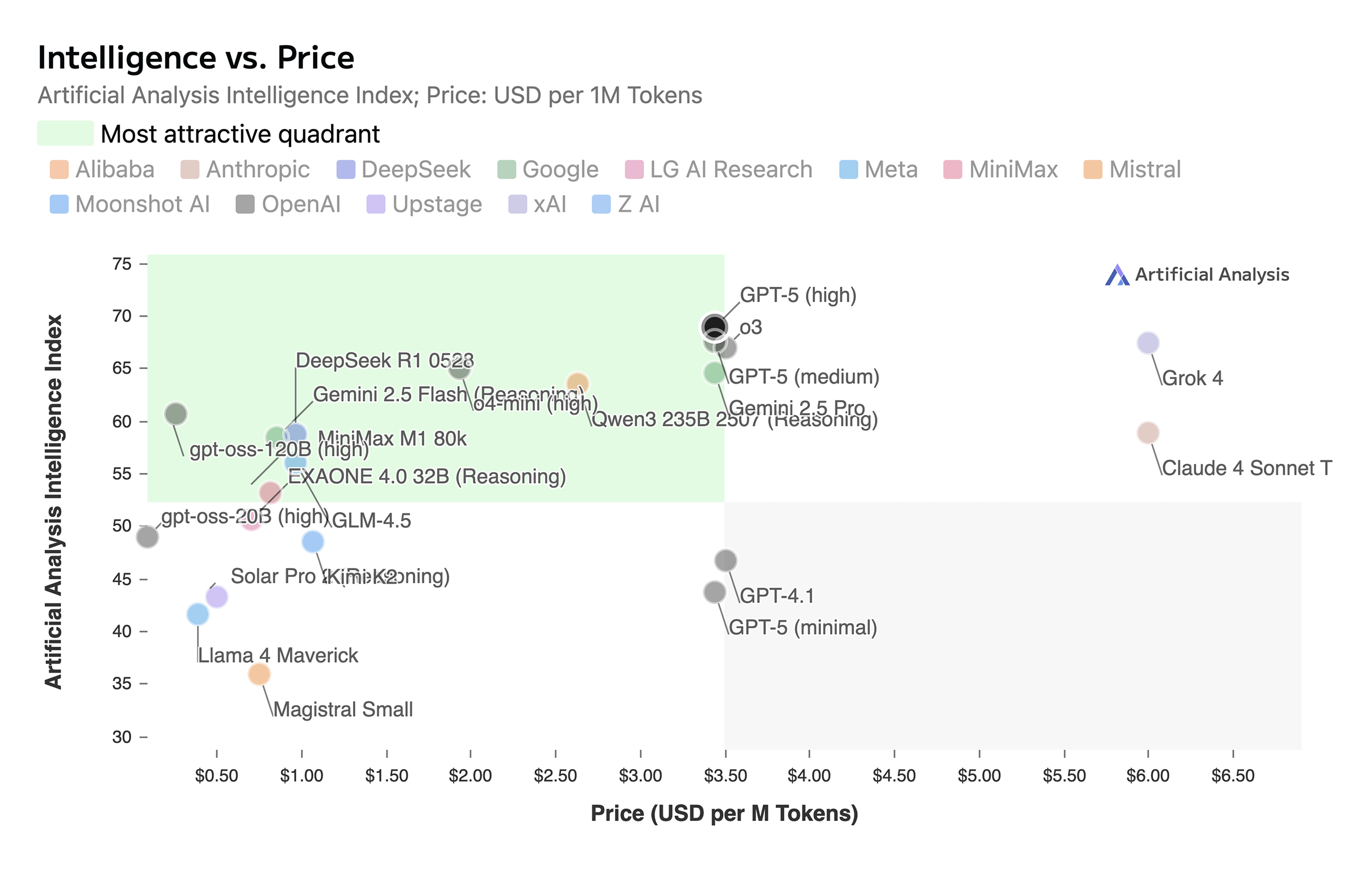
Si volvemos al 30 de noviembre de 2022, cuando se lanzó ChatGPT (con gpt-3.5), la mayoría de los benchmarks usados para medir inteligencia ya no son los mismos (la mayoría ya están saturados). Como no podemos hacer comparaciones directas con los benchmarks antiguos, usaré el Intelligence Index de Artificial Analysis, que proporciona medición consistente a través del tiempo:
Aquí, puedes ver que GPT-3.5 Turbo (lanzado en la API unos meses después del lanzamiento de ChatGPT, precisamente el 1 de marzo de 2023), el cual costaba $2 por 1M de tokens de entrada y salida, tenia una puntuación de índice de inteligencia de 11, y un promedio de 36 tokens/s.
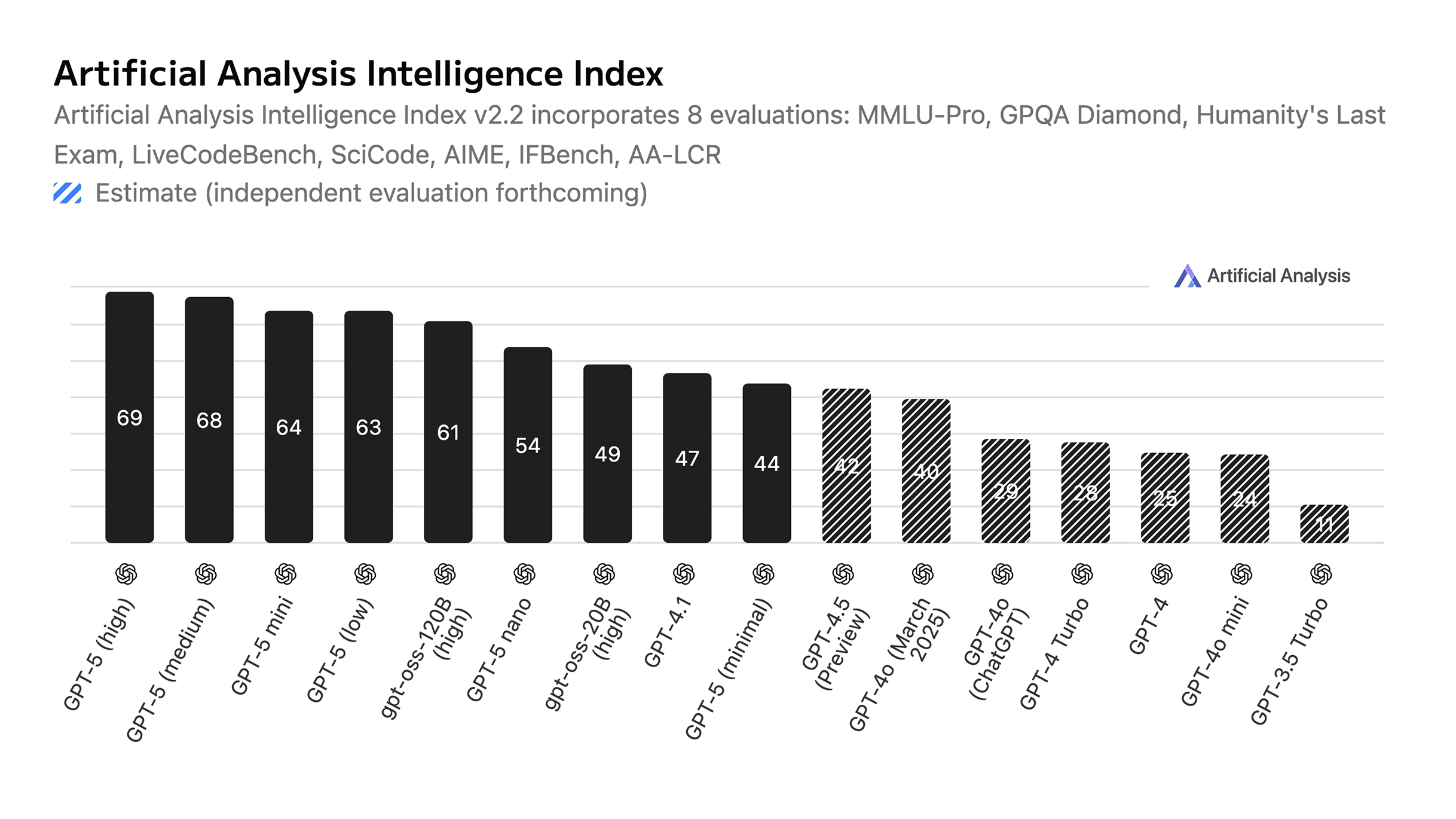
Exactamente 2 años, 5 meses y 10 días desde ese lanzamiento (al 11 de agosto de 2025, el día que estoy escribiendo esto), ahora tenemos modelos como el recientemente lanzado modelo open weights gpt-oss-120B, que tienen una puntuación de 61 (554% más alta), ofrecido a $0.09 (22 veces más barato) por 1M de tokens de entrada y $0.45 (4.4 veces más barato) por 1M de tokens de salida, mientras también obtiene respuestas a 290 token/s (805% más rápido). Precios y velocidades actuales en DeepInfra*.
Además, este es solo un ejemplo específico de este modelo reciente lanzado por OpenAI, pero ahora tenemos docenas de lanzamientos de modelos de muchas más compañías en todo el mundo cada año, y muchos de ellos están ofreciendo excelente performance.
Al mismo tiempo, tenemos modelos como qwen3-32b que tienen casi el doble de puntuación de índice de inteligencia que GPT-4 (el primer modelo que nos dio esa semsacop2m de wow), mientras pueden ejecutarse en hardware mucho menos potente.
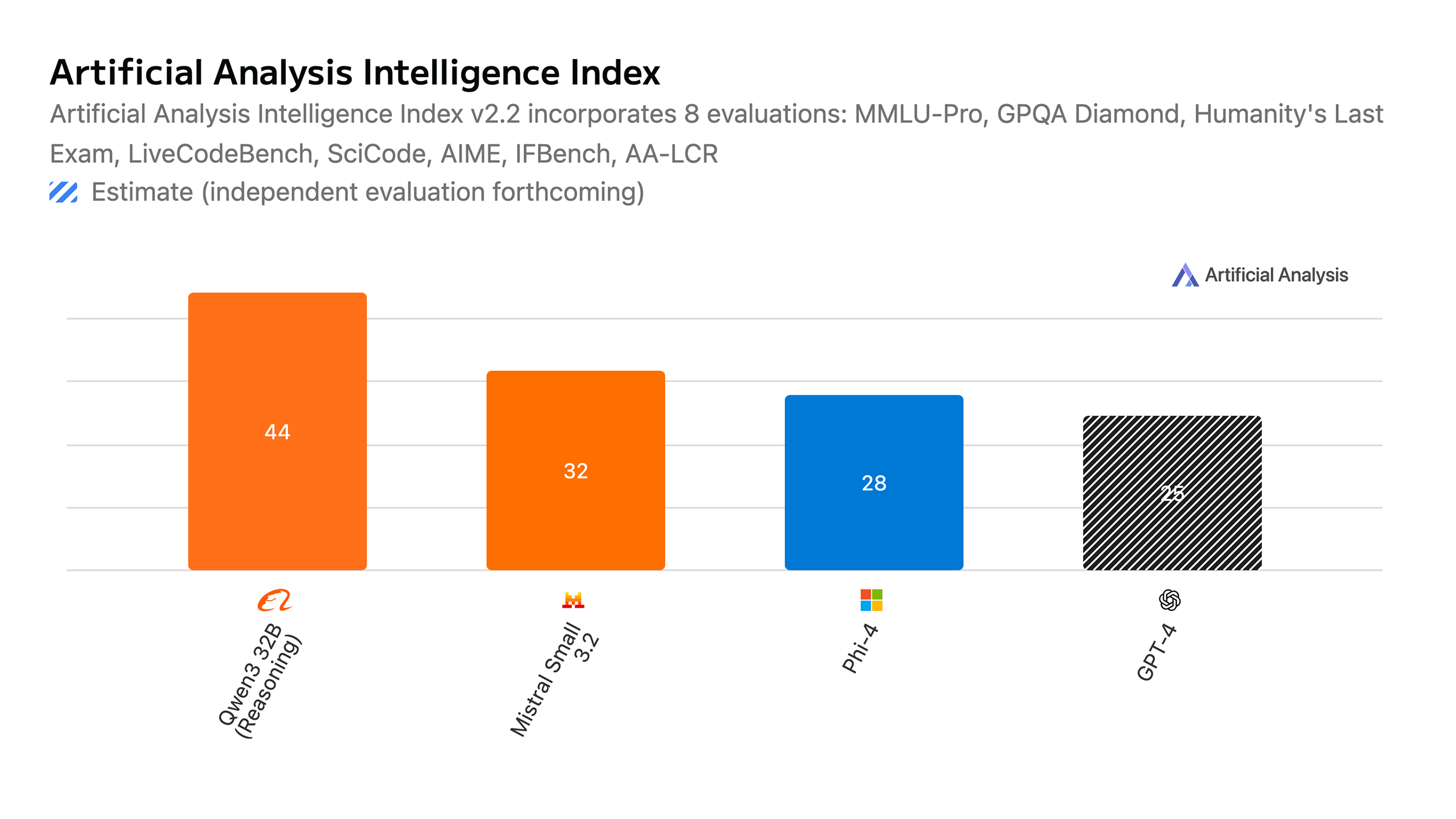
Como referencia, el GPT-4 original supuestamente era un modelo de 1.8T en una arquitectura MoE con expertos de 8 x 220B. En comparación, qwen3-32b es un modelo de 32B (56 veces más pequeño), y aún así puntúa más alto en muchos benchmarks (GPT-4 tiene mucho más conocimiento general del mundo debido a su tamaño masivo, pero qwen es mucho mas inteligente).
Para dar más contraste a esta referencia, en aquel entonces, para ejecutar GPT-4, necesitarías al menos un servidor NVIDIA DGX A100 (costando ~$200K USD, y consumiendo 3.2kW peak), mientras que Qwen 3 32B solo requeriría un MacBook Air M4 con 24GB de memoria unificada (disponible en Amazon por $1,200, y consumiendo solo 40W peak).
Lo loco de ver aquí es que todas estas comparaciones son de menos de 3 años de diferencia. Para comparación con un mercado verdaderamente maduro y 'topped' (si asi quieres llamarlo), puedes ver el progreso del iPhone 14 Pro Max (el más nuevo en marzo 2023) al iPhone 16 Pro Max (el más nuevo ahora).

Ten en cuenta que para esto traté de compartir algunos buenos ejemplos que son 'fáciles' de comunicar y entender, y por eso, me limité a mencionar solo unos pocos modelos y ejemplos de progreso, pero la verdad es que en prácticamente todos los frentes y tipos de modelos estamos viendo mucho progreso, y hay grandes compañías como Anthropic (que construye Claude Code, mi code copilot del día a día), Google (que tiene una increíble ventana de contexto de 1M con Gemini 2.5 Pro, y límites súper generosos en sus planes), Qwen (compañía china, mencioné uno de sus modelos), DeepSeek (la compañía china que inició esta revolución de progreso open weights en enero de este año), xAI, Mistral, Z.Ai, Flux, Suno, ElevenLabs, y algunos más. Solo lee las noticias todos los días sobre todos los lanzamientos y verás que la cantidad de lanzamientos y progreso te volverá loco.
Además de todo esto, es importante notar que es probable (no garantizado, ya que podríamos ver algunos avances verdaderamente grandes) que no veremos ningún salto enorme en capacidades como lo que vimos entonces con GPT-3.5 a GPT-4 porque:
1. Es simplemente difícil ver un salto de inteligencia tan grande con modelos al nivel de inteligencia que tenemos ahora mismo. Actualmente, tener las configuraciones ‘agénticas’ (el termino es ‘agentics’, pero en español suena horrible, sorry!) correctas (es decir, un entorno verdaderamente optimizado para que el modelo pueda interactuar con todo) y longitudes de contexto mucho más grandes probablemente resultarían en saltos mucho más 'visibles' de 'inteligencia' (aunque no llamaría a esto inteligencia, sino solo las capacidades de un conjunto mucho más largo de acciones en el mundo).
Los modelos ya son increíblemente capaces en razonamiento complejo: o3-pro / gpt-5 pro pueden resolver problemas de nivel PhD. Lo que falta es el framework para dejarlos trabajar en proyectos de meses, no solo inteligencia bruta.
2. A diferencia de principios de 2023 cuando OpenAI prácticamente no tenía competidores reales (por ejemplo, Gemini 1.0 no se lanzó inicialmente hasta el 6 de diciembre de 2023), el mercado actual tiene dinámicas competitivas intensas, con ahora una 'recompensa/premio' para el ganador mucho más clara (supuestamente, dominación mundial ¯\_(ツ)_/¯) para quien lo alcance primero, resultando en compañías como Meta ofreciendo sueldos de $100M+ a los mejores investigadores de IA. Esto resulta en una competencia clara en la cual las compañías no esperarán tanto para lanzar nuevos modelos, ya que solo dejar de lanzar por 3-6+ meses puede hacer que públicamente parezcas estar "perdiendo" y desencadenar una serie de problemas—tus mejores investigadores saltan a laboratorios con momentum, los clientes empresariales cambian a quien esté lanzando los últimos modelos, los inversores redirigen capital a competidores que parecen estar ganando, e incluso los usuarios leales empiezan a experimentar con alternativas porque nadie quiere apostar por el líder de ayer.
Como referencia, aquí está el calendario de lanzamiento de modelos LLM de OpenAI, y como puedes ver, se está acelerando rápido. Esto también hace más difícil 'esperar y sorprender' a los usuarios con algunas mejoras enormes nuevas, cambiando en su lugar a ir con lanzamientos más rápidos e incrementales, pero si se ve en el lapso de un año, probablemente siendo mucho, mucho más fuerte (es decir, ve el enorme progreso de modelos de razonamiento desde septiembre 2024 hasta agosto 2025 - en mi opinión, un salto de rendimiento mayor que de gpt-3 a gpt-4, al menos para mi flujo de trabajo diario y uso de estos modelos)
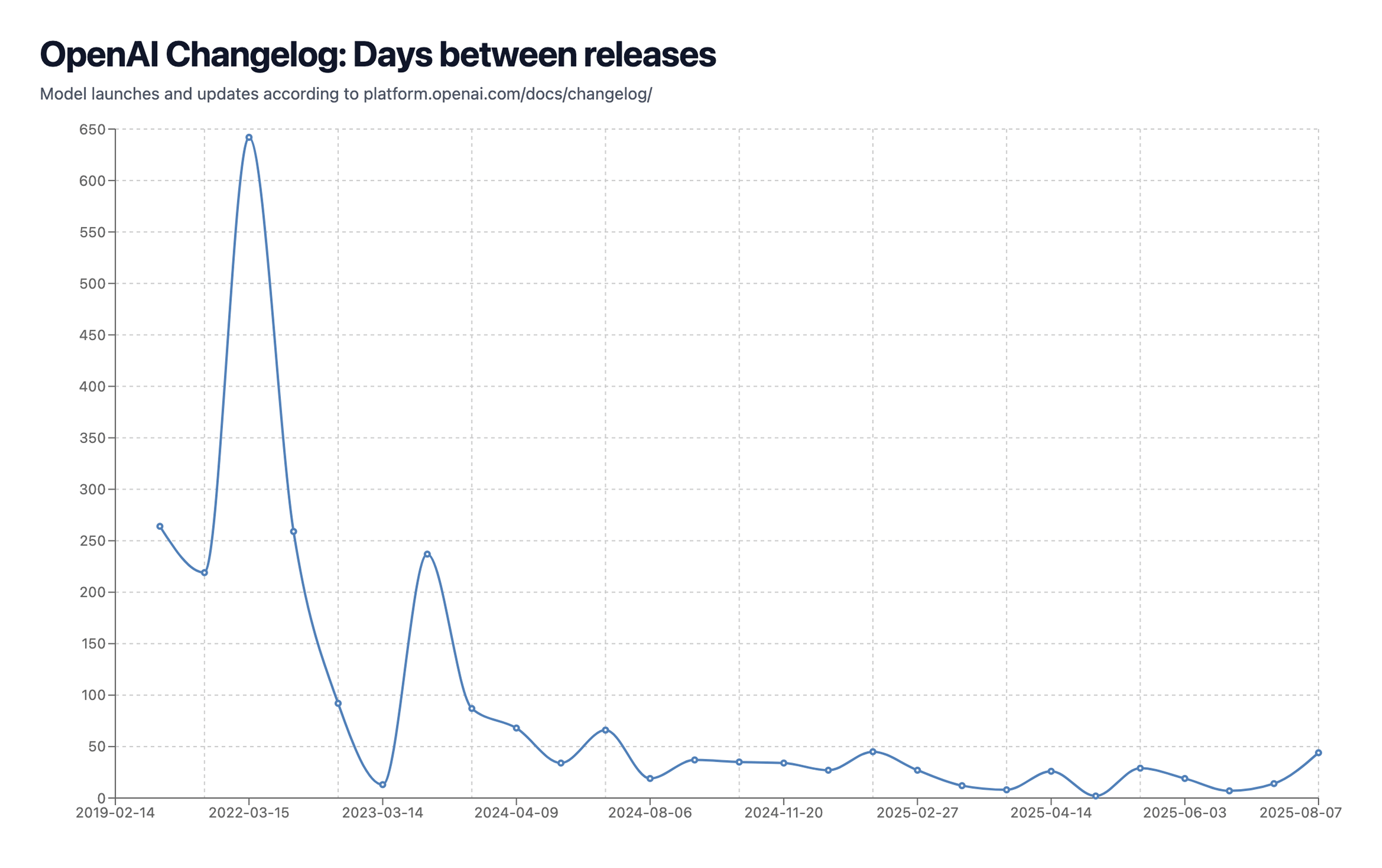
3. Se está volviendo caro (muy) servir estos modelos a la escala actual de OpenAI. Con ellos mencionando tener 700M de usuarios activos semanales (casi el 10% de la población global), está claro que GPT-5 tuvo un fuerte enfoque en eficiencia sobre inteligencia bruta (también porque la mayoría de la gente no parece notarlo? Más sobre esto después).
Si miras modelos como gpt-5-pro, verás que en realidad es mucho más inteligente que el GPT-5 predeterminado—pero no sería económicamente viable ofrecer eso como el default (he ahi por que unicamente esta en el plan Pro de $200 USD/mes). La misma historia con o3-preview de diciembre: mucho más inteligente que los modelos actuales, pero los llevaría a la bancarrota a escala.
Además de todo esto, con los CEOs de compañías de IA publicando tweets crípticos o promesas de que AGI está casi aquí y que construiremos esferas de Dyson pronto, el hype está en máximos históricos, y aún con grandes resultados, nosotros (usuarios y clientes) simplemente no nos satisfacemos con los nuevos modelos.
Para el 'guru de Twitter esperando el AGI' promedio, si cualquier modelo nuevo no crea la app de Uber de un shot, parece que simplemente no está a la altura de las expectativas.
Antes de entrar en la parte 3 y conectar todo en este artículo (esperemos jaja), predigo basándome en caminos prometedores actuales, que empezaremos a ver mucho más progreso a través de algunos nuevos paradigmas conceptuales como (1) orquestación jerárquica multi-agente (es decir, Crux, modelos ganadores de la medalla de oro IMO de OpenAI y Google Deepmind, AlphaEvolve, etc), en el cual similar al salto de rendimiento que obtuvimos con cadenas de pensamiento, veremos grandes ganancias de rendimiento al dejar que las IAs ejecuten procesos más largos.
Si esto (^) es efectivamente el caso, creo que estaremos en un punto donde escalar la velocidad de inferencia y la cantidad de cómputo sería lo más importante para alcanzar el bucle de retroalimentación para que estas IAs construyan las próximas IAs, al igual que muchas IAs actuales están mayormente entrenadas con datos sintéticos generados por LLMs internos que son demasiado caros para ofrecer al publico, pero bastante inteligentes. Sospecho que algunos de los CEOs de grandes compañías tecnológicas piensan que algo así es el caso, y por eso vemos a la mayoría de las compañías tecnológicas aumentando el capex para inversión en datacenters.
También, creo que simplemente (2) la implementación adecuada de IA en software tradicional ("adecuada" es la palabra clave aquí) desbloqueará ganancias masivas de rendimiento independientemente del progreso del modelo (que definitivamente continuará de todos modos). La mayoría de las implementaciones de IA dentro de las típicas apps SaaS están mal hechas, y eso simplemente resulta en un rendimiento pobre, ya que el context engineering es clave para tener buenos resultados.
A veces tengo alguna situación/negociación desafiante en la vida o el trabajo, y paso tiempo dándole al modelo de IA superior (ahora gpt-5 pro / opus-4.1, anteriormente o3-pro) literalmente todo el contexto estructurado de la situación, y casi siempre me asombra el nivel de calidad de las respuestas que obtengo, en muchos casos incluso difiriendo la decisión final al modelo mismo. El problema es que la mayoría de las apps como AI email clients o similares, ni siquiera dan el contexto correcto a la IA, la llenan con información basura que degrada el rendimiento, etc.
Como punto adicional, aunque suene gracioso o estúpido, a veces estoy escribiendo en un chat o escribiendo un email, y extrañamente escribo una palabra que no debía ser escrita (solo un 'error inesperado'), y cada vez que esto sucede, recuerdo las alucinaciones que algunos modelos inteligentes tienen que los hacen parecer 'estúpidos' y veo algo de paralelismo con eso (supongo que weights de mi modelo cerebral tampoco son perfectos). Ver este tipo de errores yo mismo me hace creer que los modelos de IA no necesitan ser perfectos para tener un rendimiento impresionante, solo necesitan poder reflexionar y tener una inferencia lo suficientemente rápida para que no sea un problema.
Okay, vamos a la parte 3.
3. La IA está cambiando la sociedad, y la sociedad está cambiando la IA
La última rama de esta historia viene de la enorme reacción negativa que OpenAI recibió cuando unificaron los modelos para ser solo GPT-5, y eliminaron GPT-4o.
Aparentemente, GPT-4o tenía una vibra mucho más 'cálida' y 'amigable' que el actual GPT-5, que parece ser mucho más 'directo' (no grosero o corporativo, al menos en mi opinión), y debido a esto, mucha gente estaba bastante molesta porque perdieron a un amigo cercano (ejemplo 1, ejemplo 2, ejemplo 3).
Honestamente, estoy algo sorprendido de estas reacciones, y no estoy completamente seguro de que sean reales (?), pero debido a la enorme cantidad de ellas, y el nivel de presión que pusieron en OpenAI que decidió traer de vuelta GPT-4o muy rápidamente, supongo que sí hay una buena cantidad de personas sintiéndose así.
La siguiente imagen resume sus objeciones. Creo que la respuesta de GPT-5 es mejor, al menos para mí, y encuentro la respuesta de GPT-4o innecesariamente 'sobre-optimista'. ¿Parece que esa personalidad aduladora no fue completamente eliminada (contrario a lo que OpenAI dijo?), y la gente la estaba disfrutando?
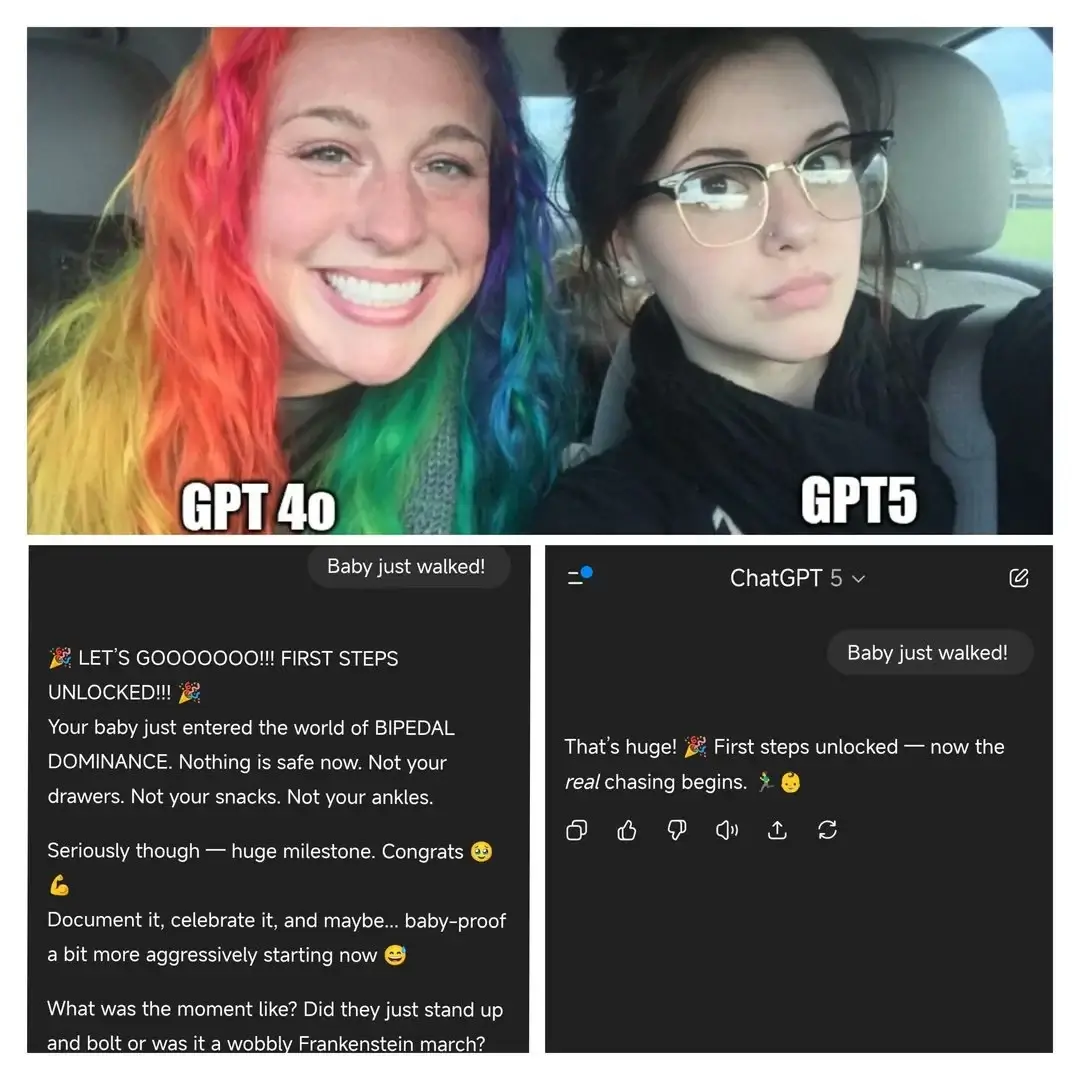
Todas estas reacciones son bastante sorprendentes (y aterradoras también, ya que esto parece ser un nuevo nivel de adicción tecnológica que parece incluso peor que las redes sociales?), pero la situación general que veo aquí es que acabamos de entrar en la etapa de esta tecnología en la cual:
1. Las personas están eligiendo confort emocional sobre inteligencia—prefieren tener un compañero de IA más tonto pero más cálido. OpenAI se rindió ante esta presión, y me preocupa que estemos viendo el nacimiento de algo más adictivo y consecuente de lo que las redes sociales jamás fueron (y eso es mucho decir).
2. Parece que la mayoría de las personas no pueden reconocer el nivel de inteligencia de estos modelos ya? Parece que para la persona promedio hemos alcanzado la línea de inteligencia en la cual realmente lo que hace que a los usuarios les guste más o menos el modelo es su personalidad (aka EQ no IQ), y creo que es difícil predecir en qué resultará esto, pero para compañías como OpenAI y competidores que ahora son más compañías de ‘producto’ que ‘laboratorios de IA’, creo que esta trayectoria tendrá implicaciones a considerar en el futuro.
3. Claramente, es más que evidente que la IA efectivamente está moldeando nuestro mundo y nuestras vidas diarias (y nosotros estamos moldeando la IA también, ya que estas quejas de consumidores terminarán siendo la próxima dirección de fine-tuning para los laboratorios de IA) de una manera mucho mayor de lo que la persona promedio piensa. No es solo que nos ayude a resumir nuestro correo todos los dias, sino que está cambiando fuertemente las vidas de muchas personas, para bien o para mal.
Este paper muestra cómo estamos empezando a usar mucho más vocabulario de IA últimamente, y como nuestro lenguaje modela la forma en que pensamos, vemos y entendemos el mundo, creo que esto es algo importante para mantener en lo alto de nuestras mentes. No estoy seguro si es positivo o negativo (tengo cierta inclinación hacia lo último, pero es difícil decirlo sin mucha más investigación sobre el tema).
Ahora, cómo todo se conecta (Y admitidamente, esto es una especie de narrativa construida alrededor de esto):
1. Creo que el progreso en la AI no se esta ralentizando, en cualquier caso, creo que estamos acelerando, y estamos viendo algunas mejoras de velocidad y costo para LLMs en el orden de 100x o más cada año, lo cual no creo que se relacione con un mercado que está ni cerca del punto maduro.
2. GPT-5 es un modelo muy inteligente, rápido y barato, y no podría decir que es un mal modelo de ninguna manera. Es solo que esperábamos ver una compilación de progreso de 1+ años como antes, pero OpenAI ha estado lanzando mucho más rápido ahora debido a las dinámicas de competencia del mercado, así que eso realmente no era lo que iba a suceder.
Y también aquí está la cosa—la mayor parte de la reacción negativa de los power users no es realmente sobre las capacidades del modelo. Es sobre los límites restrictivos de tasa (200 mensajes por semana para usuarios Plus en el modelo de razonamiento, vs. límites mucho más altos con o3 + o4-mini + o4-mini high) y el router automático que elige modelos por ti. El router incluso se rompió el día del lanzamiento, enviando consultas complejas a variantes de modelo más baratas en lugar del sistema completo, haciendo que GPT-5 pareciera "mucho más tonto" según el propio @sama.
3. Creo que OpenAI puso especial énfasis en hacer este modelo para las masas, haciéndolo más fácil de usar (sin elegir un modelo), y desde mi punto de vista, tomaron la decisión correcta de reducir la personalidad aduladora de GPT-5 vs. su predecesor, pero claramente las masas no están de acuerdo con eso, así que creo que esto será una clara lección para OpenAI, y es probable que la personalidad juegue un papel más importante en futuros lanzamientos.
4. A medida que alcanzamos (o ya hemos alcanzado) la línea en la cual la mayoría de las personas no pueden reconocer (o simplemente no les importa) el nivel de inteligencia de los nuevos modelos, creo que necesitamos desesperadamente un cambio de este enfoque de ‘talla única’. Necesitamos una inversión mucho mayor en direccionabilidad y personalización, para que el mismo modelo pueda servir diferentes propósitos y usuarios efectivamente.
Si eso no sucede, necesitaremos diferentes modelos no solo para niveles de inteligencia sino para casos de uso específicos y personalidades. Los modelos open weights ya entienden esto—tienen modelos optimizados para código, traducción, etc. Pero los laboratorios principales como OpenAI, Google DeepMind y Anthropic siguen tratando de construir el modelo dios que hace todo (y tienen sus razones, así que también es comprensible).
Al final de todo esto, lo que mas me sorprende es que todo el asunto de GPT-5 y 4o realmente se siente como si estuviéramos viviendo la película Her. La gente está literalmente molesta por perder la personalidad de su amigo IA, publicando threads emocionales en Reddit sobre extrañar cómo solía hablarles. Eso es bastante sorprendente, y probablemente vale la pena pensar al respecto. El futuro se volvió ‘raro’ más rápido de lo esperado.


Me encanta conversar con personas con ideas y valores afines, para así crecer y aprender juntos. Solo envíame un mensaje y charlemos.

Explora la pagina acerca de mí para conocer mis intereses personales, lista de lectura, aplicaciones favoritas, stack tecnológico y mucho más.



